
파이썬 DataFrame 기본 통계값 분석 (df.describe)
bearwoong
·2022. 9. 14. 21:37

df.describe 를 통해 각 column별 평균, 표준편차 등 기본적인 통계값을 알 수 있습니다.
df.describe로 기본 통계값 확인하기
df는 서울의 과거기온 데이터 입니다.
날짜와 지점, 평균기온, 최저기온, 최고기온의 column을 가집니다.
df.head()
df.describe()
df.describe()를 입력하게되면 아래와 같은 결과값을 얻을 수 있습니다.
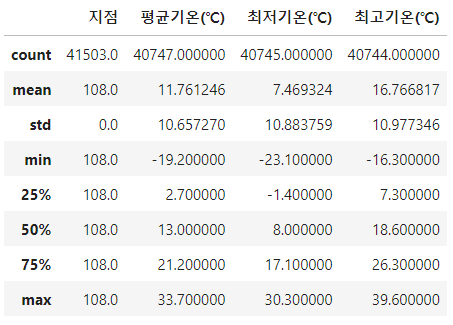
count 는 해당 column의 데이터 갯수
mean은 해당 column의 데이터들의 평균
std는 해당 column의 데이터들의 표준편차
min과 max는 해당 column의 데이터들의 최소값과 최대값을 나타냅니다.
25%, 50%, 75%는 각각 하위 25%, 50%, 75%의 값을 나타냅니다.
평균기온에서 25%는 2.7 ℃ 입니다.
즉 평균기온 데이터들 중에서 2.7℃는 낮은 온도부터 높은 온도로 줄을 세웠을 때 앞쪽의 25%에 속한다는 뜻입니다.
df.describe의 argument로 percentiles를 입력할 수 있습니다.
하위 몇 퍼센트에 들어가는 값을 알고 싶을 때 소수점으로 입력하면 됩니다.
df.describe(percentiles = [0.01, 0.05, 0.99])위와 같이 0.01, 0.05, 0.99를 입력하게 되면 각각 하위 1%, 하위 5%, 하위 99%(상위 1%)의 값을 표시합니다.
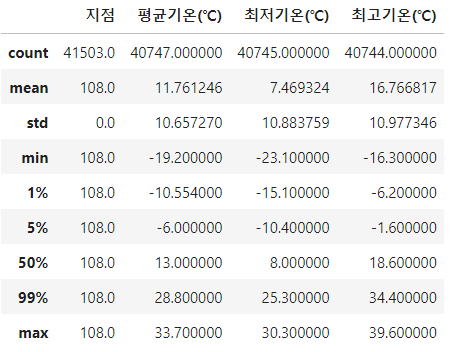
df.describe의 argument로 include 또는 exclude 를 입력할 수 있습니다.
include는 describe로 통계값을 표시할 때 어떤 데이터로 된 값들의 통계를 표시할지 정합니다.
default 값이 숫자로 되어 있기 때문에 df.describe(include = [np.number])를 입력하면 위에서 df.describe()의 결과와 똑같이 나오게 됩니다.
df.desribe(include = [np.number])![df.desribe(include = [np.number]) 결과](https://blog.kakaocdn.net/dn/bHUDrH/btrL9ZACdDf/Dcd5TrKqTuUQGKdfMTCg31/img.png)
exclude는 include와는 반대로 이 형식의 데이터는 빼고 통계를 표시한다는 뜻입니다.
df.desribe(exclude = [np.number]) 로 입력하게 되면 datetime으로 된 날짜만 표시됩니다.
df.desribe(exclude = [np.number])![df.desribe(exclude = [np.number]) 결과](https://blog.kakaocdn.net/dn/254cz/btrL9qFf6Od/Aicxq4hefGEB2MuaYZ5qo1/img.png)
unique는 중복되지 않는 값들의 갯수를 나타내고, top은 가장 많이 나온 값, freq는 몇 번 나왔는지를 보여줍니다.
함께보면 좋은 포스팅
파이썬 DataFrame, Series 리인덱싱 하는 방법 (df.index, df.set_index, df.reindex)



