
파이썬 DataFrame 정렬(df.nlargest, nsmallest, sort_values)
bearwoong
·2022. 9. 28. 20:12

파이썬 DataFrame에서 정렬할 때 사용하는 df.nlargest, df.nsmallest, sort_values에 대해서 알아보겠습니다.
이를 통해 DataFrame에 있는 가장 큰 값들, 가장 작은 값들, 오름차순이나 내림차순으로 값들을 정렬할 수 있습니다.
아래 예제에서 사용한 csv파일은 주식 종목별 종목코드, 종목명, 종가, EPS, PER 등 가격과 관련된 정보가 들어있습니다.
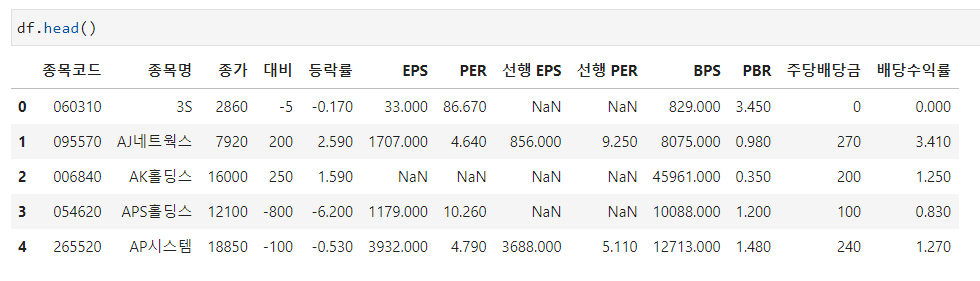
csv 파일의 head를 찍어보면 아래와 같이 나오는 것을 확인할 수 있습니다.
import pandas as pd
df = pd.read_csv("per_pbr_dividend.csv", encoding = 'cp949')
df.head()
df.nlargest(), df.nsmallest
df.nlargest( 숫자, column명 )
이 함수는 특정 column의 값들을 기준으로 가장 큰 row들을 DataFrame으로 반환합니다.
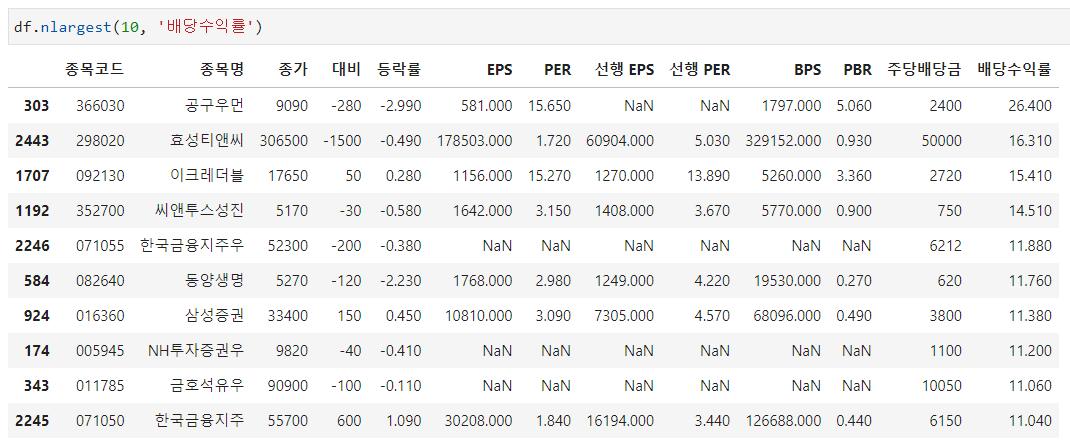
예를들어 위 DataFrame에서 df.nlargest(10, '배당수익률')로 쓰게되면 배당수익률이 높은 10종목을 골라서 데이터프레임으로 반환합니다.
df.nlargest(10, '배당수익률')
df.nsmallest( 숫자, column명 )
nlargest와 마찬가지로 특정 column의 값들을 기준으로하며 가장 작은 row들을 데이터프레임으로 반환합니다.
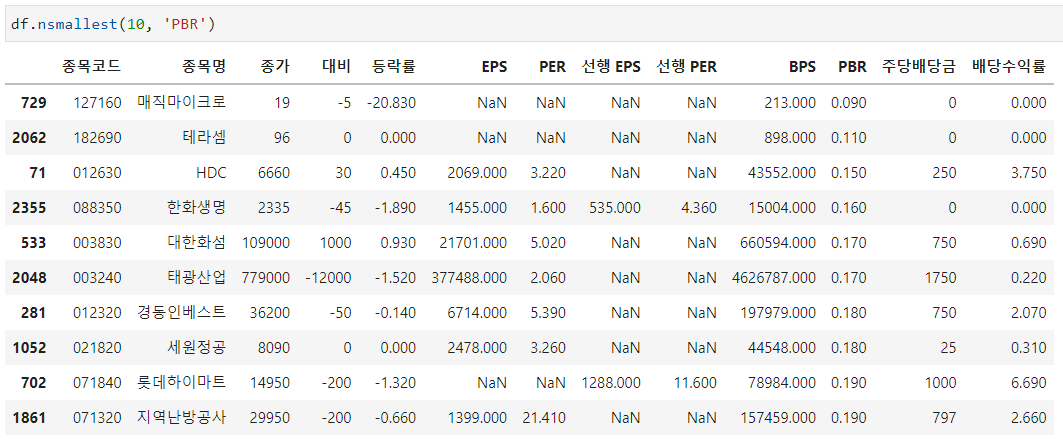
예를들어 df.nlargest(10, 'PBR')을 하게되면 PBR이 낮은 10개의 종목을 데이터프레임으로 반환합니다.
df.nsmallest(10, 'PBR')
df.sort_values(column명, ascending)
sort_values 는 특정 column을 기준으로 오름차순 또는 내림차순으로 row들을 정렬한 DataFrame을 반환합니다.
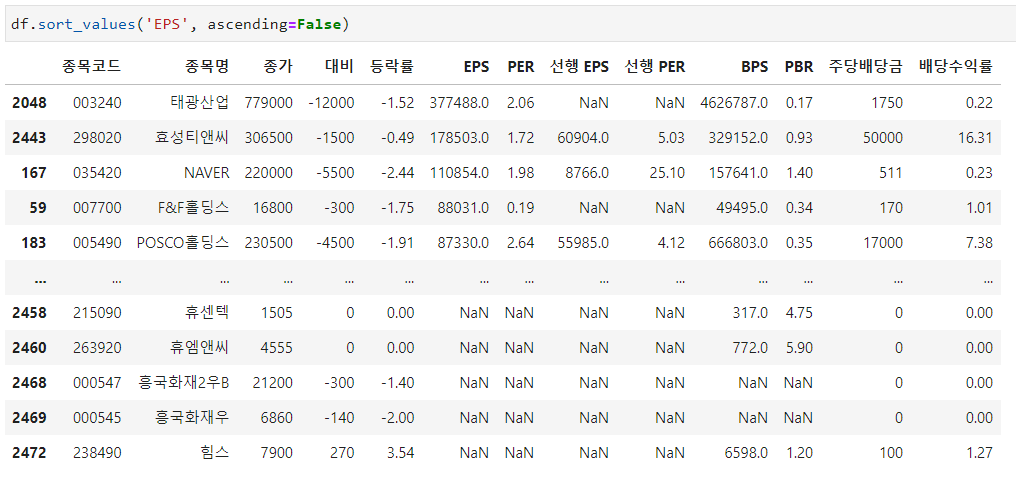
예를들어 sort_values('EPS', ascending = False)를 하게되면 EPS 값을 기준으로 내림차순으로 정렬하게 됩니다.
오름차순으로 정렬하고 싶다면 ascending = True 를 입력하면 됩니다.
sort_values('EPS', ascending = False)
함께보면 좋은 포스팅
파이썬 DataFrame 인덱싱 하는 방법(df[ ], df.loc[ ], df.iloc[ ])
파이썬 리스트 append, insert, del, sorted, len 활용하기 - 코드잇



