
파이썬 DataFrame row로 subset 만들기(df.iloc, df.loc)
bearwoong
·2022. 10. 7. 08:30

DataFrame에서 특정 row를 인덱싱하거나 row들을 선택하여 subset을 만드는 방법을 알아보겠습니다.
df.iloc 또는 df.loc을 사용하여 DataFrame의 row별로 데이터를 가져올 수 있습니다.
df.iloc과 df.loc의 가장 큰 차이점은 iloc은 숫자로 인덱싱을 하고 loc은 row명으로 인덱싱을 하는 것입니다.
아래 설명할 때 사용할 csv파일은 한국에 상장된 주식들의 종목명, 종가, EPS, PER 등 주식에 관련된 여러 데이터를 가지고 있습니다.
csv파일의 윗부분만 보면 아래와 같습니다.
import pandas as pd
df = pd.read_csv("per_pbr_dividend.csv", encoding = 'cp949')
df.head()
df.iloc[ ]
iloc은 숫자로 인덱싱을 합니다.
즉 첫 번째 row를 0으로 하여서, 두 번째 row는 1, 세 번째 row는 2 이런 식으로 나갑니다.
df.iloc[ ]과 df.iloc[[ ]]
df.iloc[0]을 하게되면 첫 번째 row인 3S의 종목코드, 종가, 대비, 등락률, EPS, PER 등을 Series 타입으로 가져옵니다.
DataFrame 타입으로 가져오고 싶다면 df.iloc[[0]] 으로 인덱싱 할 숫자를 [ ] 안에 넣어주어야 합니다.
df.iloc[0]
type(df.iloc[0])![df.iloc[ ] 결과](https://blog.kakaocdn.net/dn/cm8pA7/btrNT65y9m6/P8wYvik6KcRQfUal3U94k1/img.png)
df.iloc[[0]]
type(df.iloc[[0]])![df.iloc[[ ]] 결과](https://blog.kakaocdn.net/dn/dnqhzm/btrNT8I4Mjk/hvnobWlm40R4C6ECgev48K/img.png)
df.iloc 으로 여러 row 가져오기
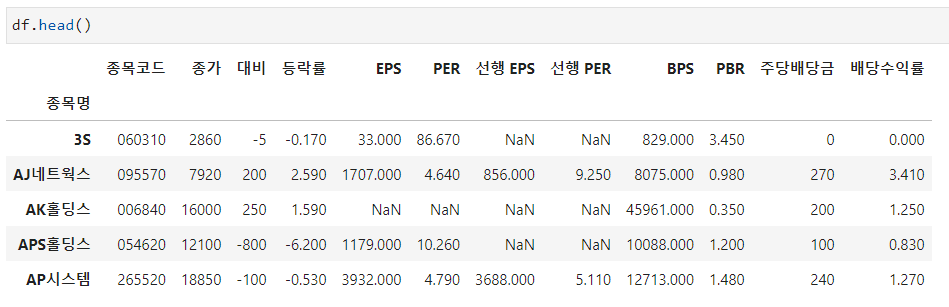
여러 row를 가져오고 싶다면 [ ]로 가져오고 싶은 row들의 인덱스를 넣어주면 됩니다.
예를들어 df.iloc[[0,2]]를 쓰면 3S와 AK홀딩스의 데이터를 가져옵니다.
(3S의 인덱스: 0 // AK홀딩스의 인덱스: 2)
물론 range 인덱싱도 가능합니다.
df.iloc[0:2]는 3S부터 AK홀딩스 전까지의 데이터(3S~AJ네트웍스)들을 가져옵니다.
df.iloc으로 특정 값 가져오기
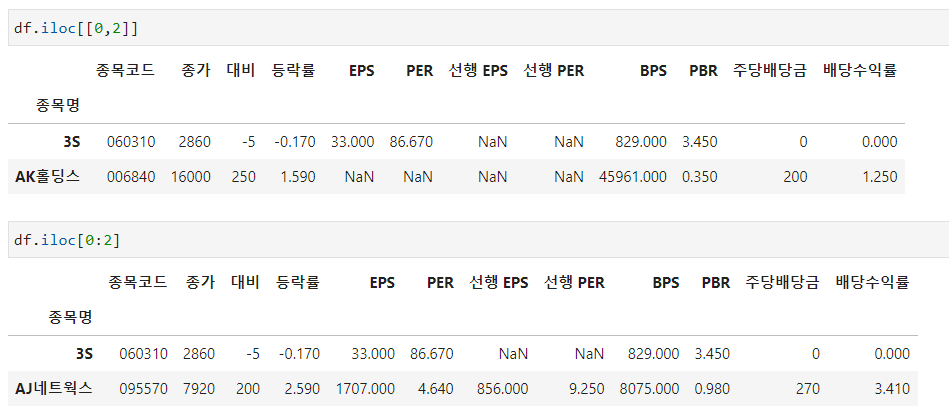
row와 column의 인덱스를 넘겨주어서 해당 값을 받아올 수 있습니다.
예를들어 df.iloc[0,1] 을 하게되면 3S의 종가를 가져오게 됩니다.
df.iloc[[0,1,2], 1] 을 하면 3S, AJ네트웍스, AK홀딩스의 종가들을 가져옵니다.
df.iloc[0,1]
df.iloc[[0,1,2], 1]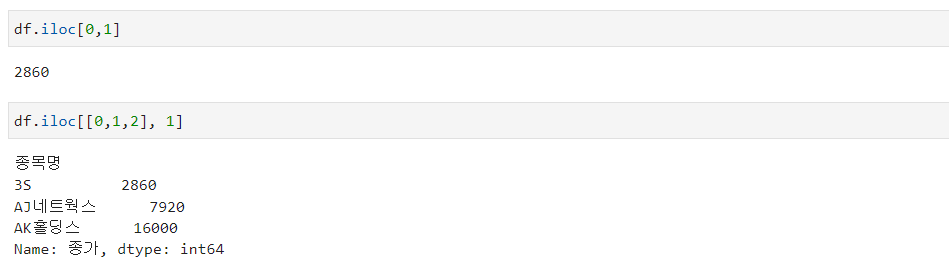
df.loc
df.loc은 iloc과는 다르게 row의 이름을 입력하여 데이터를 가져올 수 있습니다.
df.loc[ ] 과 df.loc[[ ]]
위의 iloc에서 본 것과 마찬가지로 df.loc[ ]은 Series 타입으로 한 개의 row 데이터를 가져오며, df.loc[[ ]]은 한 개 또는 여러 개의 row 데이터를 DataFrame으로 가져옵니다.
df.loc['삼성전자 ']
df.loc[['삼성전자 ']]
![df.loc[ ] 과 df.loc[[ ]] 결과](https://blog.kakaocdn.net/dn/tOrmF/btrNRPqK9bv/h8OBGrl1GVcqZfvL0qb5hK/img.png)
df.loc으로 여러 row 가져오기
[ ] 안에 row의 이름들을 넣어서 여러 row를 가져올 수 있습니다.
예를들어 df.loc[['삼성전자', 'SK하이닉스']]를 사용한다면 삼성전자와 SK하이닉스의 데이터를 가져오게 됩니다.
df.loc[['삼성전자', 'SK하이닉스']]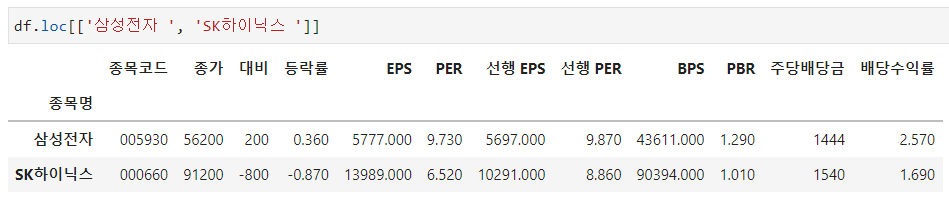
df.loc range 인덱싱
df.loc도 range 인덱싱이 가능합니다.
iloc과의 차이점은 loc은 row의 이름으로 인덱싱을 하므로 row가 정렬되어 있어야 range 인덱싱을 할 수 있습니다.
df.sort_index로 정렬할 수 있으며 df.index.is_monotonig 으로 정렬 여부를 확인할 수 있습니다.
df.sort_index()
df.index.is_monotonic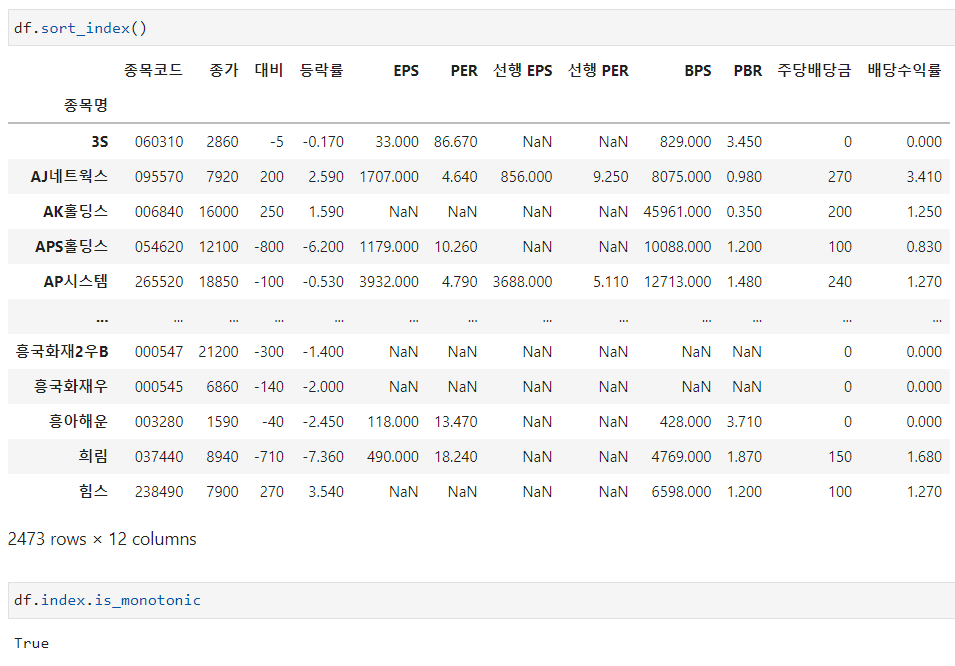
df.loc range 인덱싱
df.loc["가:다"]와 같이 range 인덱싱을 할 수 있습니다.
오름차순으로 정렬했을 때 "가"부터 시작해서 "다" 사이에 들어가는 모든 종목을 가져옵니다.
df.loc["가":"다"]![df.loc["가":"다"] 결과](https://blog.kakaocdn.net/dn/DldbY/btrNT7Q0Xvc/IDT2IzyL8byjifQfBeLEU0/img.png)
df.loc으로 특정값 가져오기
df.loc["삼성전자", "종가"]를 사용하면 삼성전자 row에서 종가 데이터만 가져옵니다.
여러 row에서 가져오려면 row 이름을 [ ] 안에 넣어 입력하면 됩니다.
여러 column에서 가져오려면 column이름을 [ ] 안에 넣어 입력하면 됩니다.
df.loc["삼성전자 ", "종가"]
df.loc[["삼성전자 ", "SK하이닉스 "], "종가"]
df.loc[["삼성전자 ", "SK하이닉스 "], ["종가", "PER"]]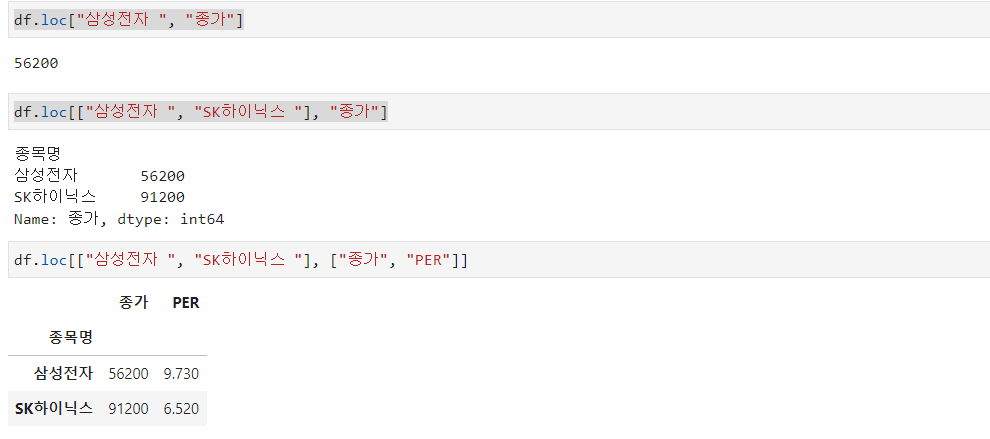
함께보면 좋은 포스팅
파이썬 DataFrame 정렬(df.nlargest, nsmallest, sort_values)
파이썬 DataFrame 인덱싱 하는 방법(df[ ], df.loc[ ], df.iloc[ ])
파이썬 DataFrame, Series 리인덱싱 하는 방법 (df.index, df.set_index, df.reindex)



